 工具箱:
工具箱: 香港:
香港: 紐約:
紐約: 倫敦:
倫敦: 東京:
東京: 悉尼:
悉尼: 香港:
香港: 新加坡:
新加坡:
T-INN(UNI BOT 配套腳本)
 321 人下載
321 人下載
321 人下載
版本:1.61
最近更新:2022.12.14


 321 人下載
321 人下載
 首次購買EA策略,全場8折優惠;首次購買後當天複購其他EA商品85折優惠。
首次購買EA策略,全場8折優惠;首次購買後當天複購其他EA商品85折優惠。
 下載EA
下載EA


 下載EA
下載EA
2022.12.16補充:
大白提醒:用T-INN獲取樣本前,最好是實盤賬戶先獲取好相關品種的曆史數據再跑腳本,否則得出來的樣本不精确,腳本運行也會報錯的
2022.12.14首次更新:
前言:今天這個腳本T-INN是和UNI BOT EA配套的,0編程基礎、小白和新手都建議直接放棄,因爲理解起來有一定難度,此腳本涉及的内容以神經網絡和深度學習爲主,本文作者并非計算機科班出身,僅能憑着有限的理解說個大概,還望各位彙市編程大師多多指點。
由于T-INN是腳本不是指标,大白目前的一鍵導入僅支持indicator和experts的文件夾,大白會先T-INN放在指标文件夾裏,大夥點擊下載後,手工在indicator指标文件夾把文件移到Scripts腳本文件夾裏。
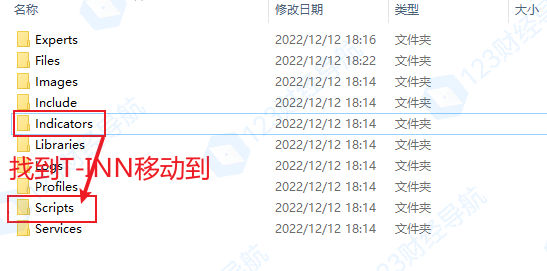
接着回到MT5腳本處,右擊刷新,即可使用。
T-INN全稱:Target-Intel NeuroNet
運行環境:Windows Server 2016
(因爲要配套UNI BOT,所以T-INN運行環境需和前者一緻)
運行前準備:至少要留出2~3天時間來訓練模型(這也是一再推遲上線的原因)
運行腳本的原理:
UNI BOT的編程團隊獨立開發了T-INN這套非零級的神經網絡系統,其團隊定義爲第一級架構複雜性的神經網絡,目前在學術界上尚未相關正式定義。
原理較複雜,因爲涉及到其他神經網絡的架構,具體的放到文末再詳細講解。
如何運行T-INN腳本:
(不懂原理的直接按着下面幾步操作即可)
①最好是在MT5運行,真實帳戶,平台最好選擇至少5~10年以上;
②選擇你想優化的品種,周期爲H1,運行大白上下載的T-INN1.61的腳本;
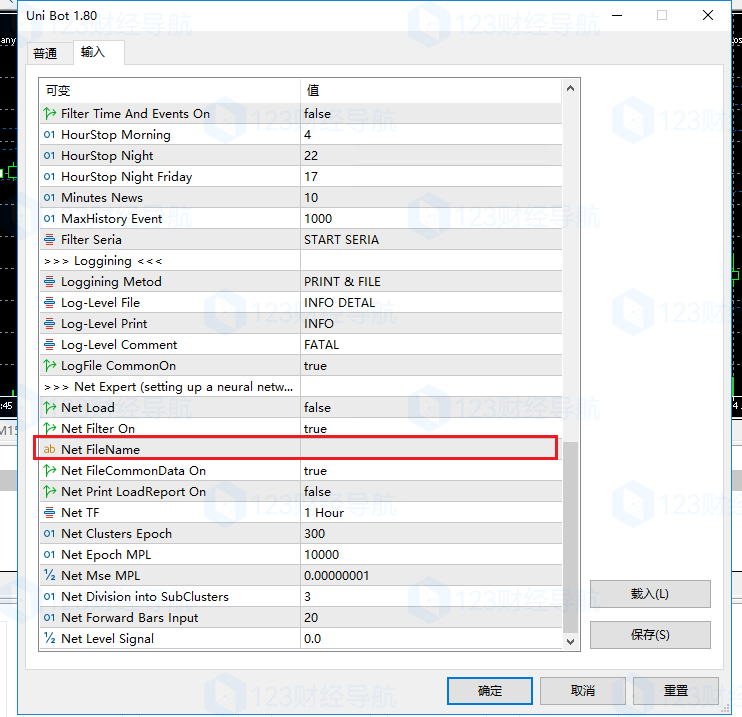
③初步加載參數,參數介紹如下
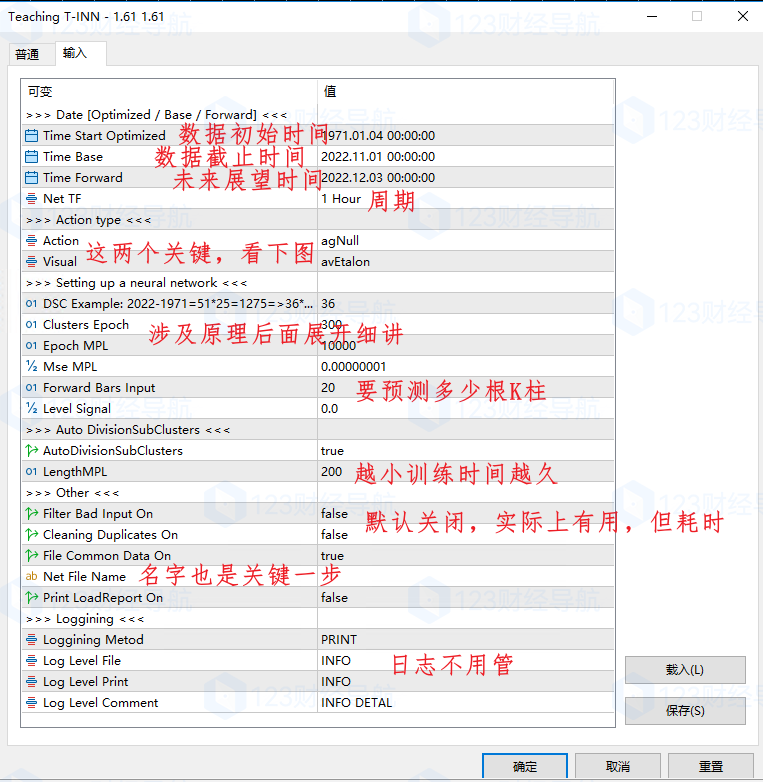
④接下來就是根據自己需求設定了,例如默認初始樣本數據時間start optimized可以改成2000.01.01 00:00:00以後的,過早的數據反倒會影響樣本的辨識度。time base 可以改成較現在的時間早一個月,半年,一年,主要目的就是留出時間差來校正神經網絡預測的行情和真實的行情的差異,所以可以設定爲2021.12.01 00:00:00。time forward則是期望看到的預測行情,例如2022.12.20 00:00:00。

後綴名是.net。
然後在第二次、第三次加載腳本的時候,要在net file name的位置填上文件名全稱,包括後綴.NET。
⑨以上設定完畢後,初步的1.0樣本就獲取完畢了,我知道你看了可能有點懵,大白這邊做個參數改動小結:
初次加載:自定義時間、action和visual都得改、lenthmpl得改;
第二次加載:時間和初次一緻、action和visual都得改、lenthmpl和初次一緻、net file name要填;
第三次加載:時間和初次一緻、action得改、lenthmpl和初次一緻、net file name要填;
⑩那問題來了,我們做了這麽多,目的是什麽?目的就是爲了獲得那份net文件,在UNI BOT EA使用的過程中,在EA參數裏導入該文件,輔助EA進一步大數據運算。

所以要想玩動這款UNI BOT EA,還是需要花一些時間和功夫的。目前中文外彙EA圈尚未看到有任何人講解T-INN腳本以及UNI BOT EA的使用,大白也是花了一點時間,才弄明白相關使用方法。剩下的篇幅我們就拓展一下神經網絡的架構,歡迎留言補充。
我們先通過一張動圖就可直接了解ANN神經網絡的基礎:
神經網絡是個大類,不是我這個新手能講明白。
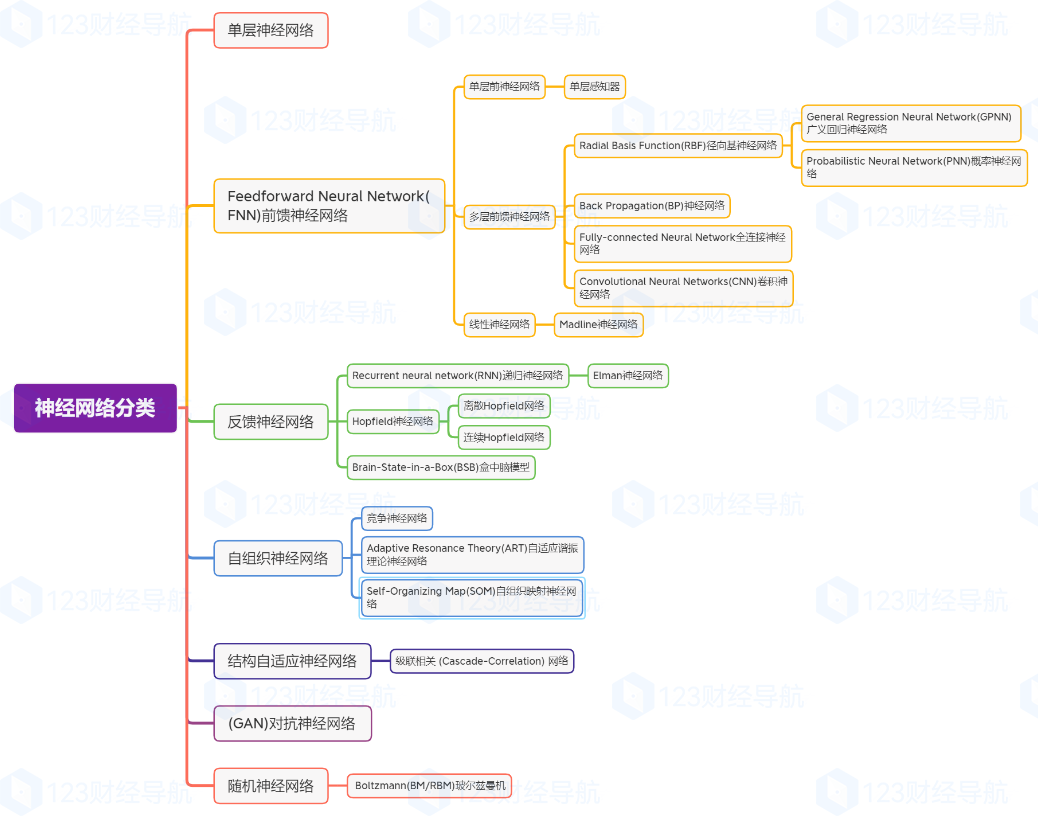
看UNI BOT提到的幾個神經網絡架構都屬于FNN前饋神經網絡
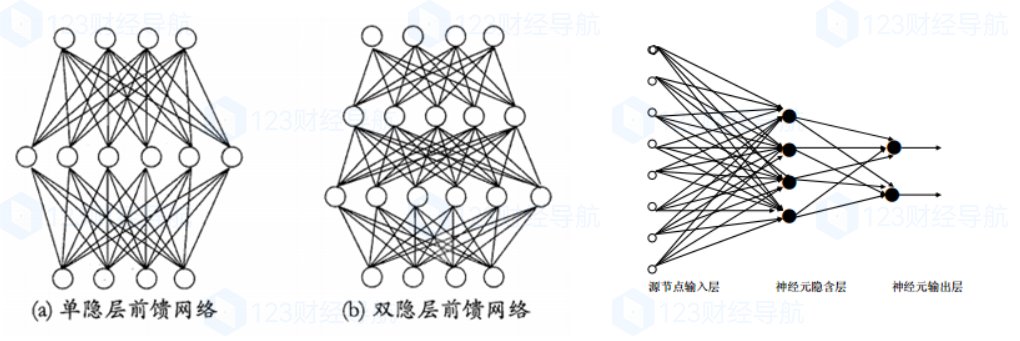
其中PNN和GRNN歸類于RBF,可以用下面這幾張圖理解一下:
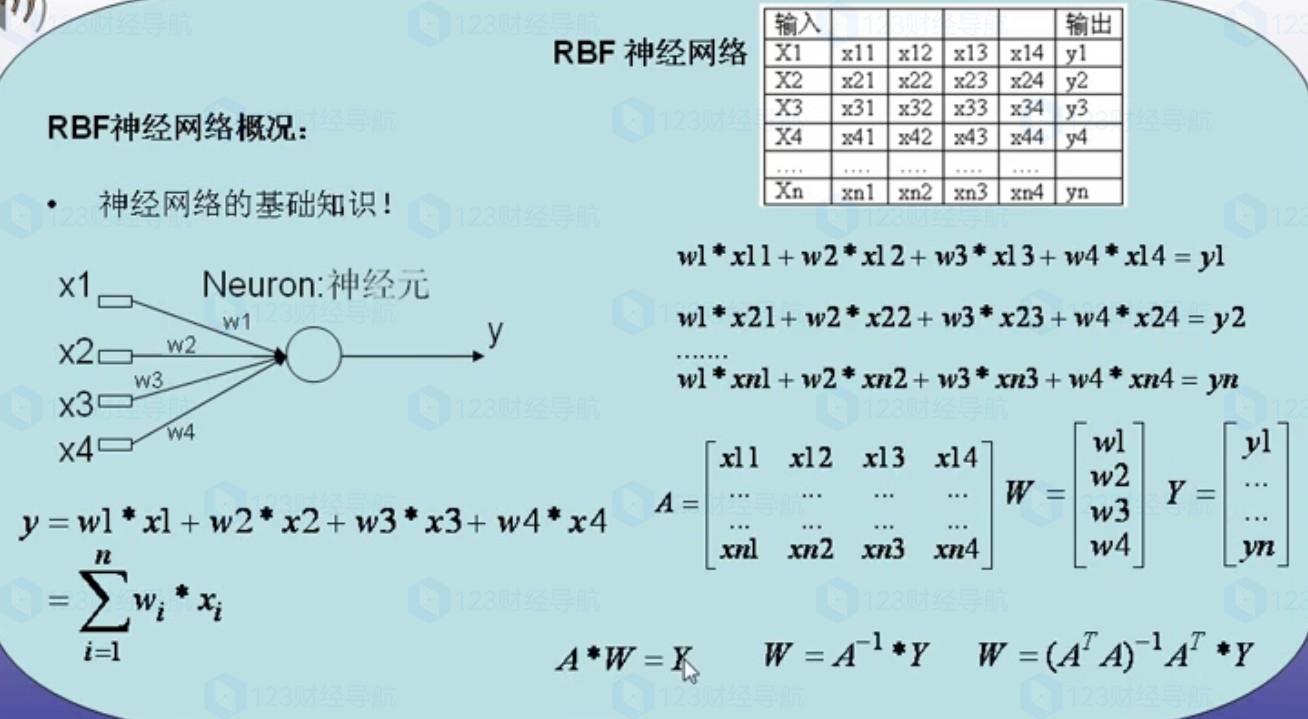
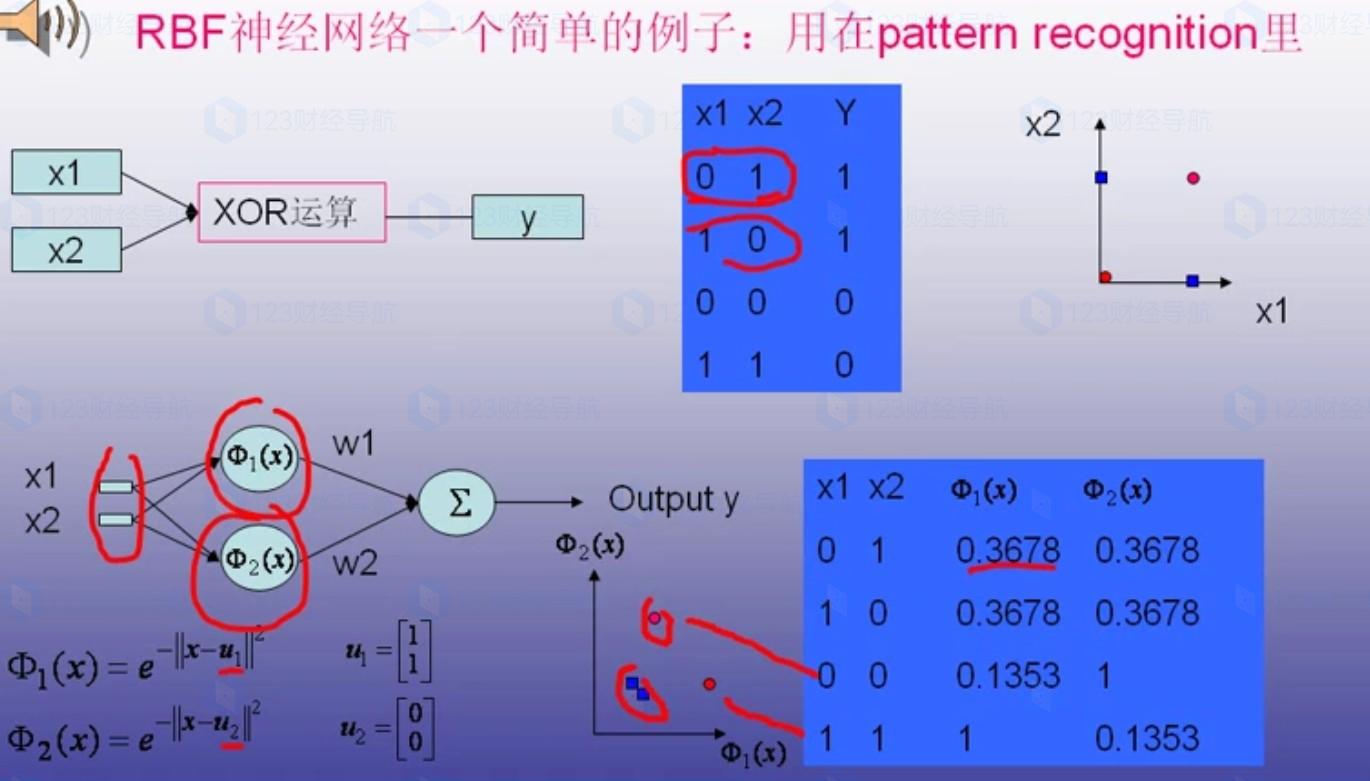
如果圖片沒看懂,大白一句話總結就是:RBF的主要作用是将原有的空間數據通過西格瑪的再次運算,整理成新的有對稱的空間數據,這麽一講,懂了不?
至于西格瑪的公式有哪些,沒有限制,隻要數據經過公式後,有辦法找出對應關系就行。
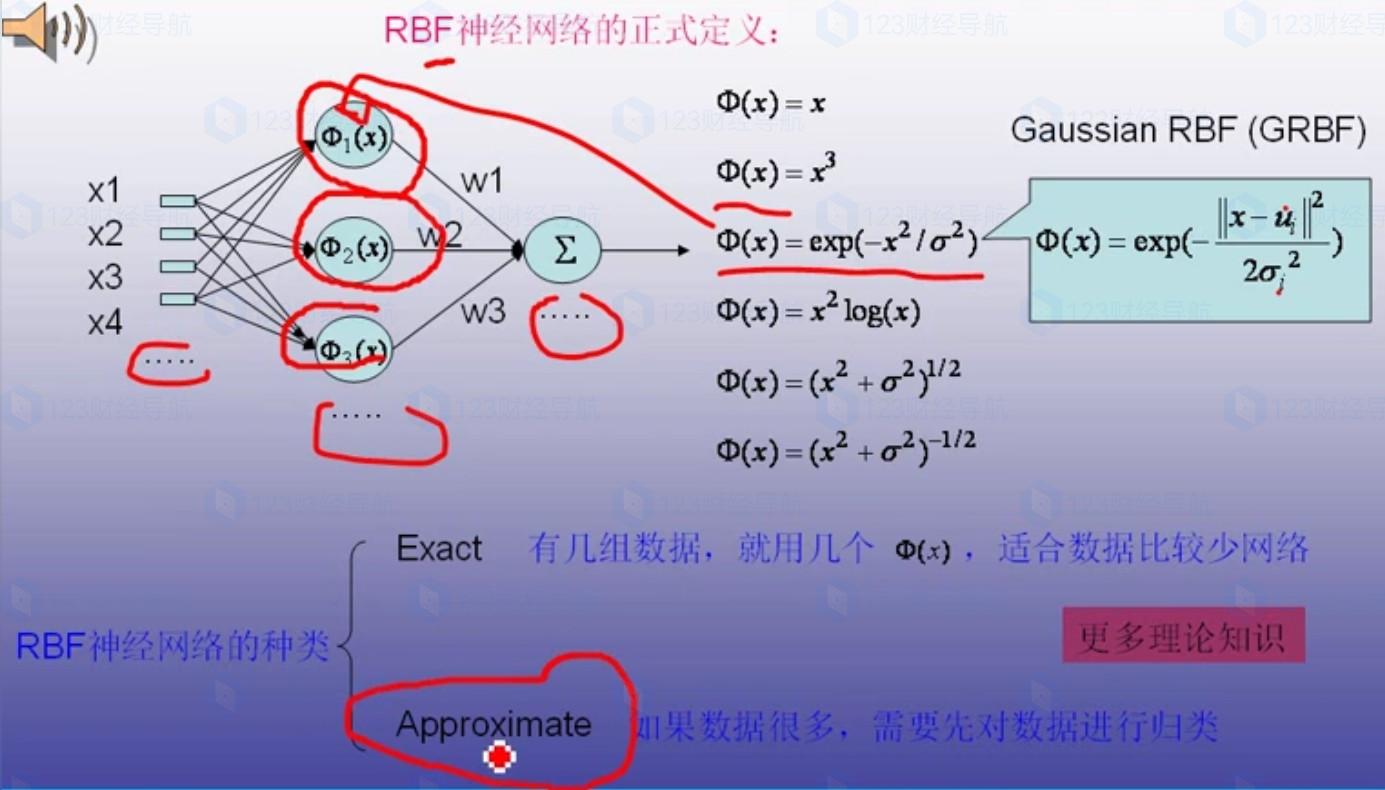
計算的難度和計算的時長,就得看初始數據的樣本大小了,邏輯上理解不難,難的在于公式的羅列以及矩陣的計算。
RBF、PNN、GRNN的優點:
1.非線性映射能力和學習速度都很強;
2.PNN用于求解分類、GRNN用于求解回歸;
3.各層級神經元數目比較固定,易于硬件實現;
RBF、PNN、GRNN的缺點:
1.沒有能力解釋自己的推理過程;
2.把一切問題的特征都變爲數字,把一切推理都變爲數值計算,其結果勢必是丢失信息;
3.隐層基函數的中心是在輸入樣本集中選取的, 這在許多情況下難以反映出系統真正的輸入輸出關系, 并且初始中心點數太多; 另外優選過程會出現數據病态現象。
T-INN參考的框架是MLP和MADALINE,前者主要爲多層感知器,後者是多層線性神經網絡。
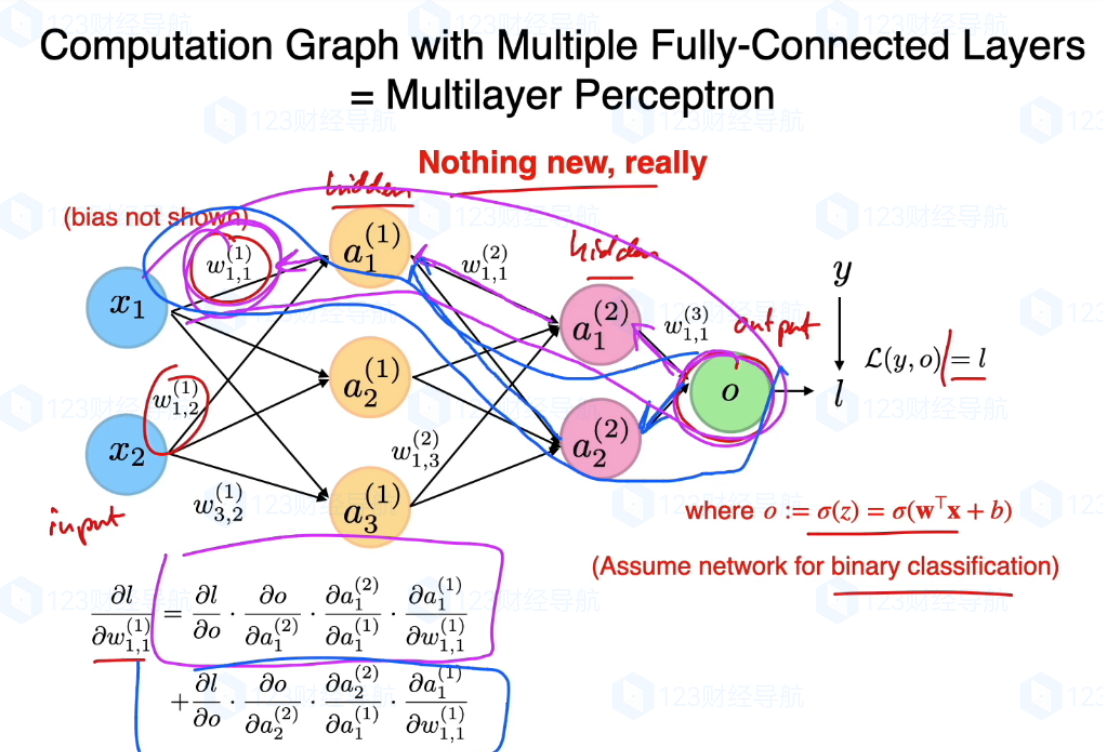
MLP已被證明是一種通用的函數近似方法,可以被用來拟合複雜的函數,或解決分類問題。主要優勢在于其快速解決複雜問題的能力。MLP是傳感器的推廣,克服了傳感器不能對線性不可分數據進行識别的弱點。
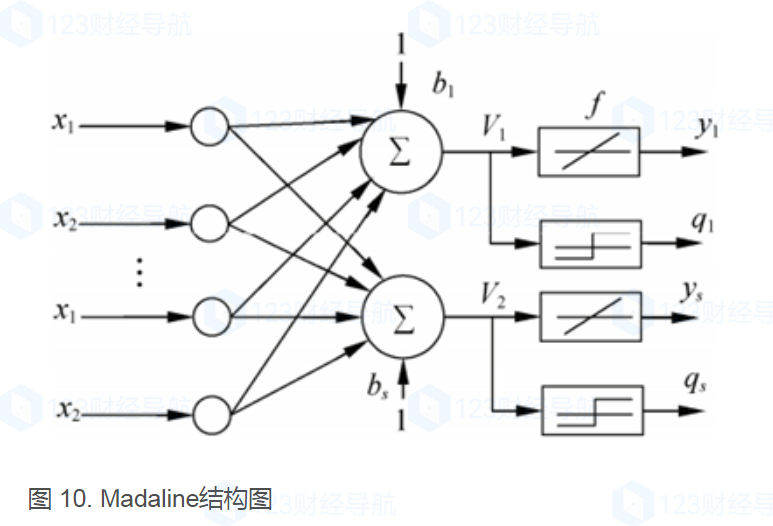
Madaline架構中輸入層和adaline層之間的權重和偏移量是可調的。
如果要推斷不可預測的數據,則需要使用MLP和Madaline,但當數據達到一個臨界值時,學習效率将大幅下降,不管期間你公式如何優化,終究還是會因爲基數過大導緻計算緩慢,效率變低,結果失真。同時,又得考慮時間成本,例如你花了一周的時間訓練出一個預測樣本,但這樣本的數據僅能預測1天的數據,花7天的時候得到1天的樣本,因爲準确性的偏差,成本實在過高。

理解神經網絡以及弄懂腳本的運行以及如何跟EA做結合還有不斷反複測試出優化,均耗了大白大部分精力,學識有限,今日暫且介紹到這裏。
通過編者附帶的回測數據,按照其想法的樣本包,回測出來的數據幾乎有過半跑不過默參,但大白認爲,該EA的架構是創新的,思路是創新的,也是有想象空間的,也希望未來外彙量化的賽道上能有更多類似EA的出現。










删除后无法恢复
删除后无法恢复