 工具箱:
工具箱: 香港:
香港: 纽约:
纽约: 伦敦:
伦敦: 东京:
东京: 悉尼:
悉尼: 香港:
香港: 新加坡:
新加坡:


近日,EBC金融在欧洲央行(ECB) 的经济公报(Economic Bulletin)上看到了一篇报告,Covid-19的大流行加速了国际机构和欧洲央行使用大数据&机器学习来实时分析商业周期。
我们之前在「EBC金融交易前瞻」系列中发布过多篇有关机器学习在交易中的应用,今天,带大家来一睹机器学习在大型国际机构中的身影。
使用机器学习和大数据分析商业周期
由 Dominik Hirschbühl、Luca Onorante 和 Lorena Saiz 编写
以往,欧洲央行和经济分析师主要依靠官方统计数据、软数据(soft data)和调研来评估经济状况。尽管可以获得大量高质量的常规数据,但数据集的发布滞后于参考期后的几天或几周到几个月不等。出于这些原因,欧洲一直在寻找利用更及时获取数据的方法,并在预测与政策制定相关的指标时采用更复杂的方法来提高准确性。
近年来,政策机构开始探索新的数据来源和替代性的统计方法,以实时评估经济活动。金融危机以来,他们加大力度,系统地利用微观和调查数据,更好地衡量总消费、投资和劳动力市场的变化。
与此同时,技术进步允许用户开始检查非常规来源,例如来自报纸文章、社交媒体和互联网的文本数据和图像以及来自支付端的数据。现在还可以使用替代统计方法,例如回归树、神经网络,它们可以充分利用从这些数据源中获得的潜在见解。
新型冠状病毒 (COVID-19) 的大流行加速了这一趋势。
欧洲的政策制定机构最近开始将结构化和非结构化大数据纳入经济分析。大数据可以是结构化的——例如在公司层面的财务报表上的大型财务数据据——也可以是非结构化的,非结构化数据包括从互联网收集的大量实时数据(例如互联网搜索量、来自 Twitter 和 Facebook 等社交网络的数据、报纸文章)到从非官方来源(例如交易平台)获得的大量数据和支付系统或基于 GPS 的技术)。
结构化数据,例如来自金融和支付交易的数据,可以为评估总消费和经济活动提供关键的实时信息。
非结构化大数据,近年来利用报纸文本数据来理解和预测商业周期的情况显着增加。在商业周期分析中,来自报纸和社交媒体的文本数据已被用于构建可能与宏观经济波动相关的“情绪”等不可观察的变量。
同样,互联网搜索的使用也开始出现在短期预测模型中。多项欧元体系研究表明,互联网搜索可以提供有关未来消费决策的信息。最近的例子包括将谷歌搜索数据与欧元区汽车销售联系起来的分析,使用谷歌搜索数据来强化德国 GDP 的预测模型,以及利用基于谷歌搜索的综合指标来预测西班牙的私人消费。
在评估劳动力和住房市场的紧张程度时,基于互联网的数据也有帮助。对美国劳动力市场的分析表明,包括基于谷歌的求职指标可提高失业预测的准确性,尤其是在中期(即未来 3 至 12 个月)。
对于房地产市场,意大利的分析发现,基于来自房地产服务在线门户网站的网络抓取数据的指标可以成为房价的领先指标。
在大流行期间,谷歌搜索与工作保留计划和裁员相关的主题,提供了对大流行和相关政策措施的强大影响的早期洞察。此外,欧元区职位发布和招聘的在线数据可作为官方统计数据的补充。
使用高频数据监测 EA-4 劳动力市场
由 Vasco Botelho 和 Agostino Consolo 编写
此框显示了高频数据如何有助于监测大流行期间欧元区的劳动力市场情况。
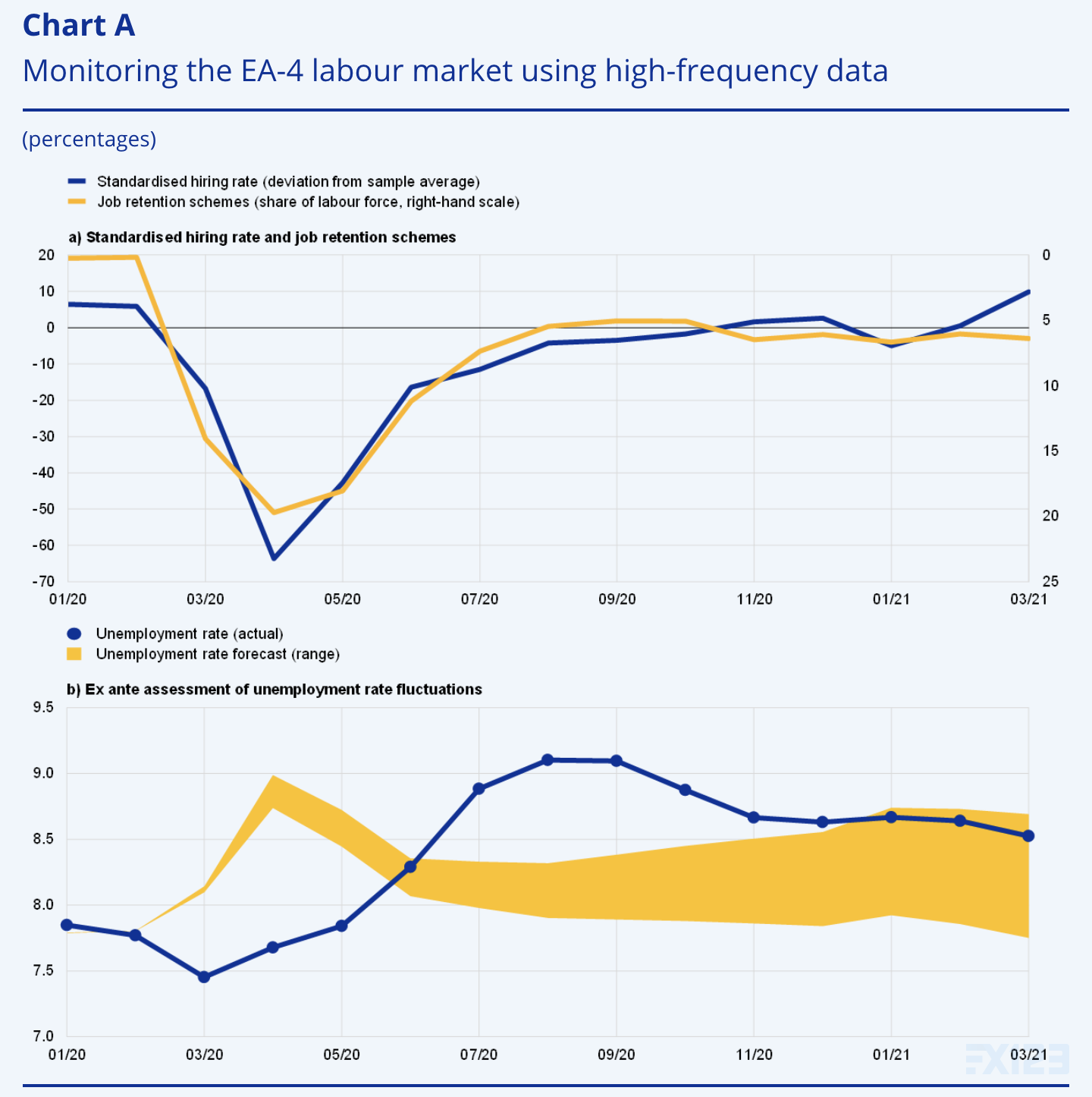
资料来源:欧盟统计局、LinkedIn、德国就业研究所 (IAB)、ifo 研究所、法国劳工、就业和经济部、意大利国家社会保障研究所、西班牙社会保障和移民部以及欧洲央行工作人员的计算。
从一组高频指标中总结信息的一种有效方法是使用经济活动跟踪器。下图提供了一个由欧洲央行设计的欧元区每周经济活动跟踪器的示例。同样,欧盟委员会的联合研究中心和经济金融事务总局一直在通过将传统宏观经济指标与大量非常规、实时和极其多样化的指标相结合来追踪 COVID-19 危机。
他们开发了一个工具箱,其中包含一系列不同的模型,包括线性和非线性模型以及几种机器学习方法,以利用大量指标来预测 GDP。
欧元区每周经济活动跟踪器
由 Gabriel Pérez-Quirós 和 Lorena Saiz 编写
自大流行开始以来,几家中央银行和国际机构通过结合几个高频指标开发了实验性的每日或每周经济活动跟踪器。
例如,纽约联邦储备银行制作的每周经济指数 (WEI) 结合了美国经济的七个每周指标。
基于类似的方法,德意志联邦银行发布了德国经济的每周活动指数 (WAI),该指数结合了九个每周指标,但还包括月度工业生产和季度 GDP。
欧元区经济活动追踪器
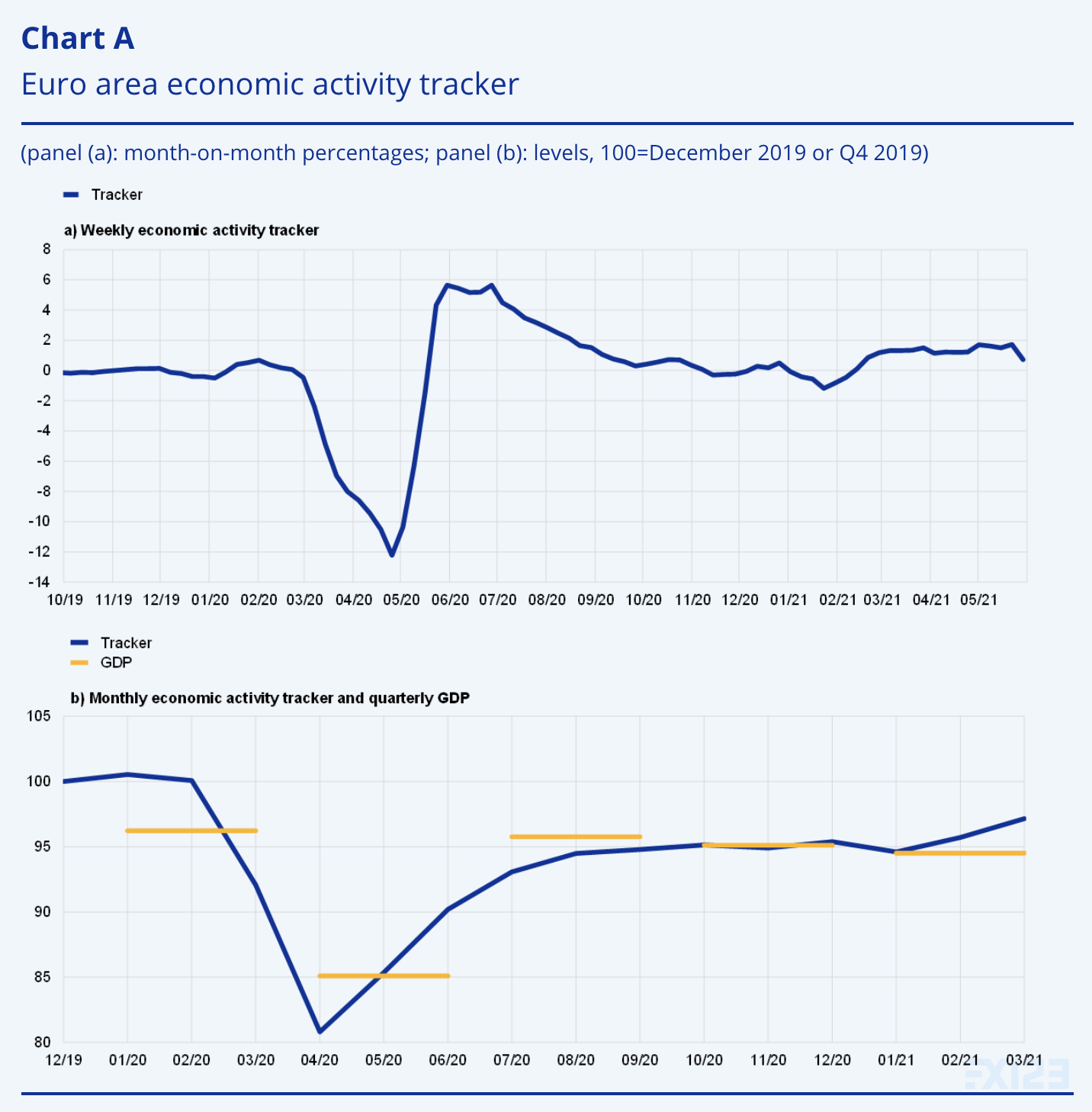
资料来源:欧洲央行工作人员的计算和欧盟统计局。
注意:最新的观察结果是针对跟踪器的 2021 年 5 月 29 日当周和针对2021 年第一季度。
ML 方法的第一个关键优势是它们能够从大量非结构化数据中提取和选择相关信息。
ML 方法的第二个关键优势是它们能够捕获非常普遍的非线性形式。由于存在金融摩擦和不确定性,宏观经济学中变量之间的非线性和相互作用很常见。
一些工作发现 ML 方法可用于宏观经济预测,因为它们可以更好地捕捉非线性因素。例如,这些方法可以捕捉金融状况和经济活动等之间的非线性关系,从而更准确地预测经济活动和经济衰退。
COVID-19 大流行是非线性的重要来源。大流行期间,许多宏观经济变量记录了与过去值范围相距甚远的极值。诸如线性时间序列分析之类的计量经济学方法试图在过去的数据中找到平均模式。如果当前数据非常不同,从过去的模式线性推断可能会导致有偏差的结果。
中央银行、欧盟委员会和其他机构已经调整了它们的预报框架,以捕捉非标准数据。
机器学习技术还是用于捕获大量现象的主要工具,否则这些现象将无法量化。
由 Julian Ashwin、Eleni Kalamara 和 Lorena Saiz 编写
本专栏展示了欧元区的经济景气指标,这些指标来源于欧元区四个最大国家的主要国家语言的报纸文章。
这些指标每天都会更新,包含及时的经济信号,可与采购经理人指数 (PMI) 等知名情绪指标中的信号相媲美。此外,它们可以显着改善欧元区实际 GDP 增长的临近预测。
欧元区 PMI 和基于报纸的情绪指数
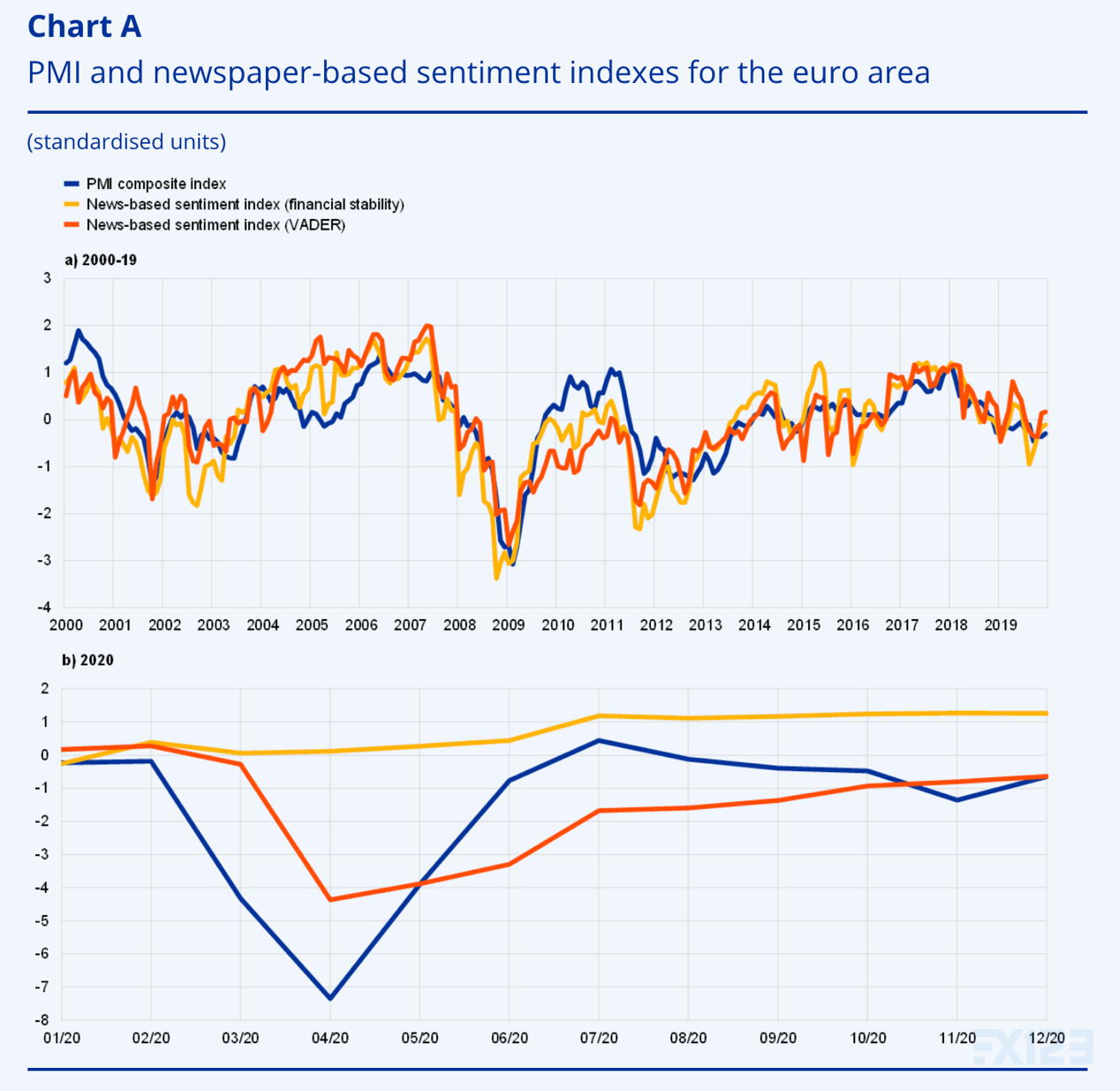
资料来源:欧洲央行工作人员计算、Factiva、IHS Markit 和欧盟统计局。
注:基于新闻的情绪指标基于欧元区四个最大国家的报纸文章。PMI 综合指数和基于新闻的情绪指标使用历史均值和方差进行标准化。
预测的准确性
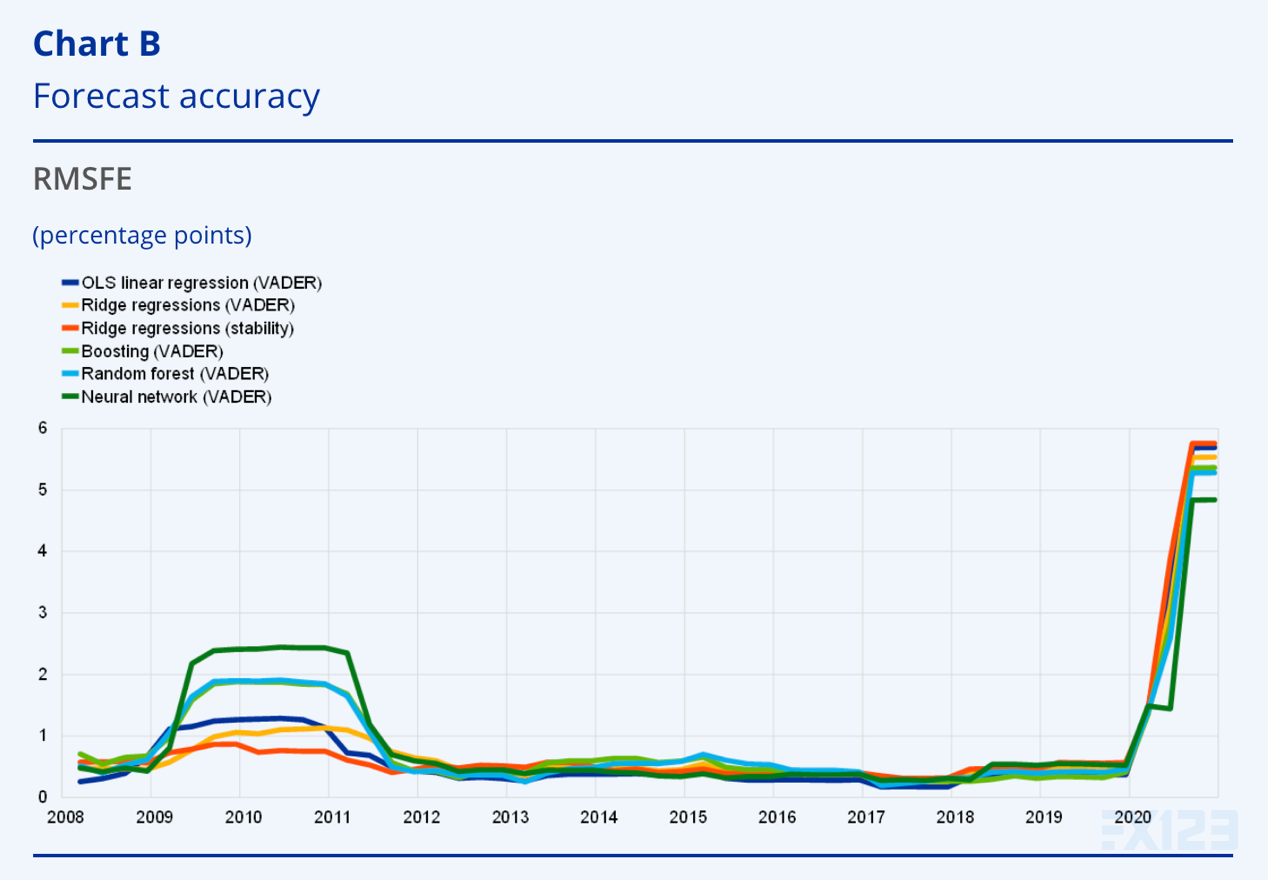
资料来源:欧洲央行工作人员的计算。
注意:该图表报告了八个季度滚动窗口内的 RMSFE。预测在参考季度的第一个月末更新。参考变量是截至 2021 年 3 月 24 日的实际 GDP 增长年份。
由 Andrés Azqueta-Gavaldón、Dominik Hirschbühl、Luca Onorante 和 Lorena Saiz 编写
下图描述了如何将大数据和机器学习 (ML) 分析应用于不确定性文本数据的测量。与“经济情绪”类似,不确定性无法直接观察到,只能使用替代指标来衡量。
欧洲央行最近的研究通过将机器学习算法应用于报纸文章,在四个最大的欧元区国家建立了一个 EPU 指数。
这种方法的主要优点是它可以很容易地应用于不同的语言,而无需依赖关键字,此功能使其不太容易出现选择偏差。此外,这种方法检索报纸文章中关于总体经济政策不确定性(例如财政、货币或贸易政策不确定性)的主题。这对于经济分析特别有用。
消费(a)和投资(b)对经济政策不确定性冲击的脉冲响应图
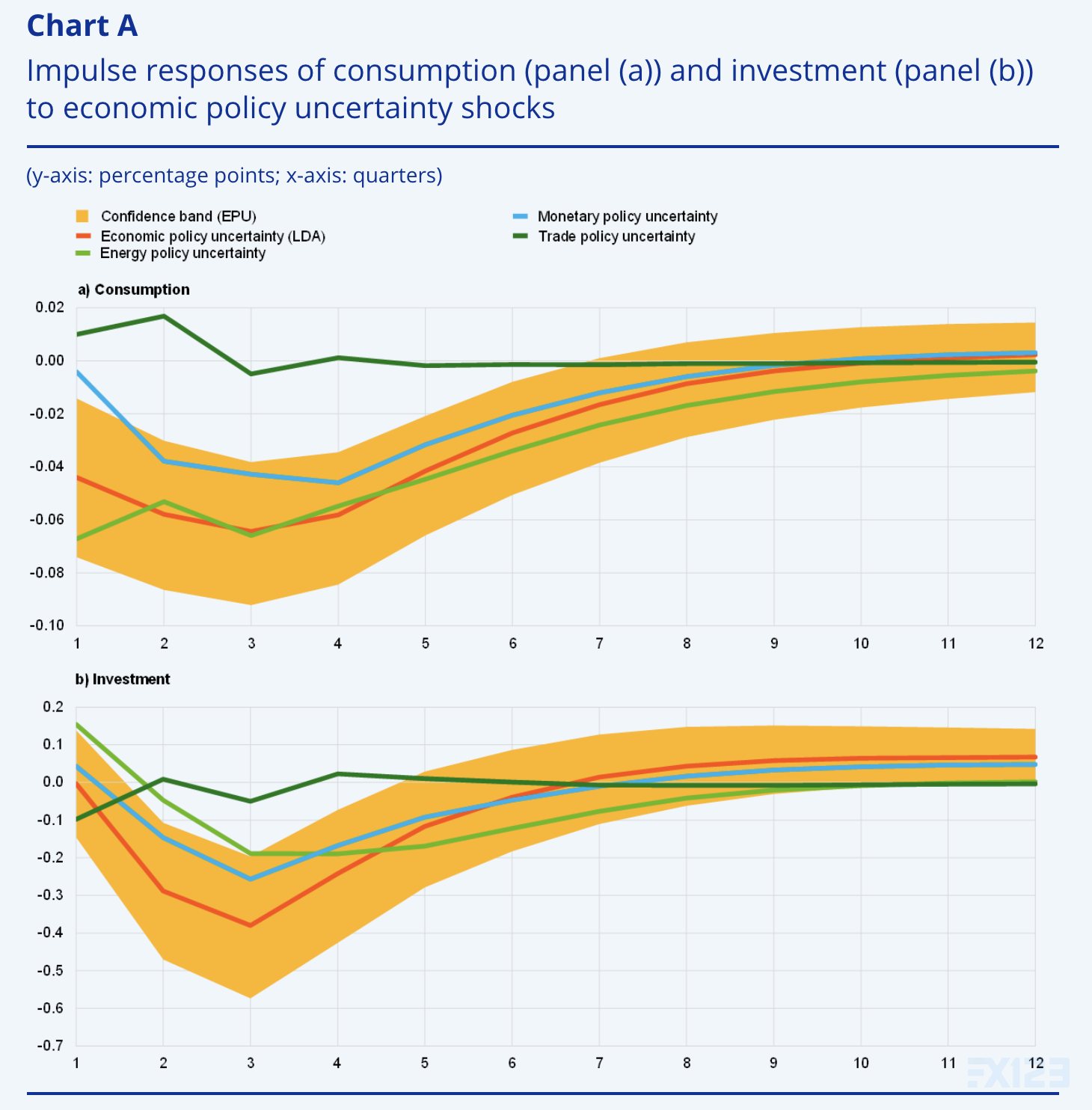
资料来源:Azqueta-Gavaldón 等人和欧盟统计局。
注:脉冲响应(Impulse response)说明了消费和投资对每个经济政策不确定性措施的一个标准差正冲击的响应。它们是用贝叶斯结构向量自回归(SVAR)估计的,冲击是用Cholesky分解法确定的,变量的顺序如下:商品和服务出口、经济政策不确定性衡量标准、私人消费、机械和设备投资、影子短期利率和欧洲STOXX。所有的变量都是季度增长率,除了影子短期利率它是水平的。估计期为2000年至2019年。不确定性度量已标准化,因此冲击的大小具有可比性。
本文讲述了大数据和机器学习方法如何运用在商业周期趋势分析中。
大数据使得人们可以使用更广泛的及时指标进行预测(例如基于文本或基于互联网的指标),尽管在某些情况下这可能会带来可复制性和问责制问题。例如,基于文本的情绪指标特别有用,因为与基于调查的指标相比,它们可以以更高的频率和更低的成本自动生成。
由于统计推断的问题,目前这些工具不能被视为标准数据和方法的完全替代品,但是可以作为补充。机器学习方法可以帮助克服大数据的缺点并充分发挥其潜力。当与大数据结合时,机器学习方法就能够胜过传统的统计方法,并提供经济发展的准确图景。尽管机器学习具有良好的预测性能,但方法的复杂性通常使得其难以对预测进行修订。目前,提高机器学习方法来捕捉因果关系仍是最大的挑战。





